

Como comentamos en el anterior capítulo, el proceso de mejora genética se basa en la recogida de información de los animales, el procesado de dicha información (normalmente mediante el sistema BLUP) hasta la obtención de un índice genético (que indica su valor para los caracteres que se están seleccionando), y la selección mediante ese índice genético de los mejores animales para cruzar en pureza, con el objetivo de mejorar los caracteres seleccionados en la siguiente generación.
A continuación se explica con más detalle el proceso de recogida de información.
Si se quiere mejorar un determinado parámetro productivo el primer paso es recoger información sobre ese parámetro, por lo que la selección genética debe empezar siempre por la recogida de datos en los animales que se quieren seleccionar.
Hay muchos tipos de datos que se pueden recoger de un animal, aunque pueden agruparse en:
- Morfológicos: tienen que ver con la morfología del animal. Entre éstos se encuentran: color de capa, conformación del animal, aplomos, posición de las orejas…
- Productivos: relacionados con sus cualidades como productores de carne. Parte de éstos son: velocidad de crecimiento, índice de conversión, capacidad de ingesta, porcentaje de magro en la canal, porcentaje de partes nobles en la canal, o medidas relacionadas con la calidad de la carne (pH, terneza, pérdidas por goteo…).
- Reproductivos: miden la capacidad reproductora del animal. Entre otros, se encuentran la prolificidad, capacidad lechera (o visto de otra manera, peso medio al destete), longevidad del animal, número de mamas viables, porcentaje de nacidos muertos, fertilidad media…
Según sea la orientación que se desee dar a la selección, se miden unos u otros caracteres. Si se está seleccionando una línea materna, se medirán fundamentalmente caracteres reproductivos (aunque también se recogerán datos del resto), mientras que si la línea que se está seleccionando es paterna (productora de verracos para IA), se medirán especialmente caracteres productivos.
Hay que comentar dos particularidades derivadas de todo este proceso de toma de datos:

- Para una mejor estimación del valor genético de un animal, se requiere saber su genealogía, luego siempre ha de saberse cuál es el padre y la madre de dicho animal. Esto obliga a hacer cubriciones monospérmicas, y a tener perfectamente registrados tanto la madre como el padre en todos los partos.
- Todo este proceso requiere que el animal esté controlado individualmente en todo momento. Esto obliga a la identificación individual desde el momento del nacimiento. A continuación ponemos un ejemplo de identificaciones según el tipo de animal:
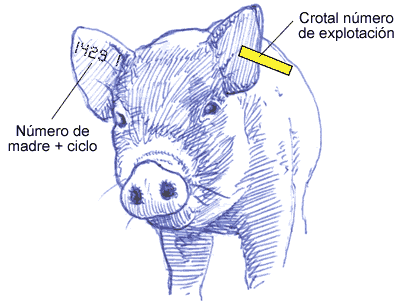
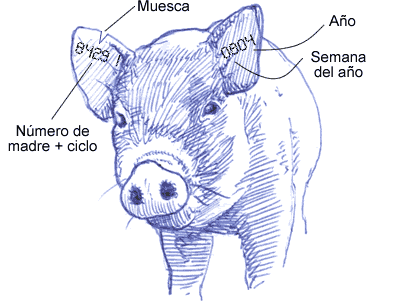
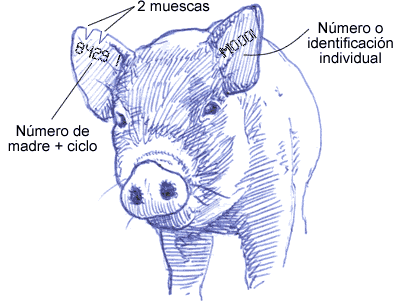
Como se observa, según se asciende en el escalafón genético, la identificación se va especificando más, hasta llegar a la identificación individual de las bisabuelas. Hay que tener en cuenta que, si se pierde la identificación individual del animal, ese animal ya no puede usarse para la selección, ya que no se sabría ni su genealogía ni sus datos anteriores.
Para la recogida de datos, las granjas de selección suelen disponer de estaciones de testaje, que son alojamientos en los que se pueden controlar una serie de datos (ingesta, etc...) y preparados para realizar el testaje: medición de una serie de parámetros que van a servir para calcular el índice genético de ese animal. Estos testajes se suelen realizar sobre los 180-200 días de vida. A continuación se pone un ejemplo de una hoja de testaje, con los datos recogidos:
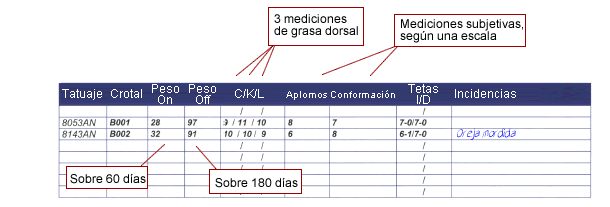
Con los datos de este testaje, más los datos existentes de la genealogía de este animal (padres, abuelos, tíos, etc.…), el programa informático basado en el sistema BLUP elabora un índice genético, que servirá para seleccionar, dentro del grupo de animales, los que se estima que son genéticamente mejores para los caracteres que estamos seleccionando. Estos animales son los que se destinarán a cubrir en pureza, descendiendo el resto al siguiente escalón.
Hay que decir que hay datos (los correspondientes a la calidad de la canal y la calidad de la carne) que no se pueden tomar directamente en los animales a seleccionar, ya que requieren el sacrificio del animal. Con este tipo de registros lo que se hace es tomar los datos de parientes cercanos (normalmente hermanos completos, es decir, animales de la misma camada del que se está seleccionando). De este modo, se pueden dedicar, por ejemplo, la mitad de los machos de la camada al sacrificio y recogida de los datos, y la otra mitad a selección.
En cuanto a los datos reproductivos, se suelen recoger todos los que se recogen en una granja normal, tales como cubriciones -siempre monospérmicas-, partos, destetes, abortos, etc., más una serie de datos añadidos (pesos de los animales al nacimiento y destete, números de machos y hembras, espesores de grasa dorsal, ingestas…).
Es aconsejable, en estas granjas, que el programa informático de gestión que se use permita la recogida de todos estos datos, y su volcado posterior al programa específico de mejora genética de la empresa. Esto evita duplicar la entrada de datos, además de dar más información para el manejo diario de la granja, evitando posibles errores. Vemos un ejemplo de pantalla en que se pueden recoger los datos del testaje anterior.
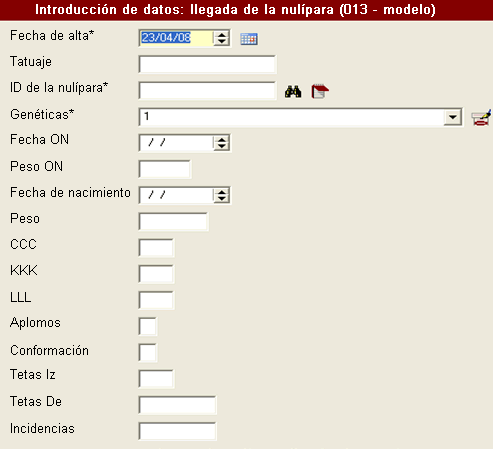
Y una tarjeta de cerda con información importante para hacer los seguimientos individuales y de genealogías:
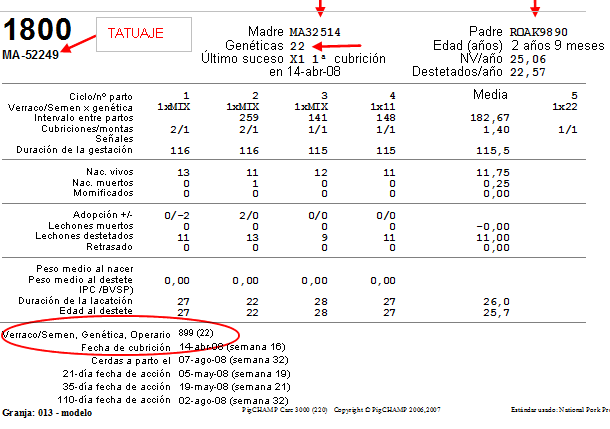
En el siguiente artículo explicaremos como se usa toda esta información recogida, como se procesa y el resultado final, es decir, el resto del proceso de selección genética.
